[ZKP 讀書會] Trust Token Browser API
Trust Token API 是一個正在標準化的瀏覽器 API,主要的目的是在保護隱私的前提下提供跨站授權 (Cross-domain authorization) 的功能,以前如果需要跨站追蹤或授權通常都使用有隱私疑慮的 Cookies 機制,而 Trust Token 則是希望在保護隱私的前提下完成相同的功能。
會在 ZKP (Zero-knowledge proof) 讀書會研究 Trust Token 主要是這個 API 採用了零知識證明來保護隱私,這也是這次讀書會中少見跟區塊鏈無關的零知識證明應用。
問題
大家應該都有點了一個產品的網頁後,很快的就在 Facebook 或是 Google 上面看到相關的廣告。但是產品網頁並不是在 Facebook 上面,他怎麼會知道我看了這個產品的頁面?
通常這都是透過 Cookie 來做跨網站追蹤來記錄你在網路上的瀏覽行為。以 Facebook 為例。
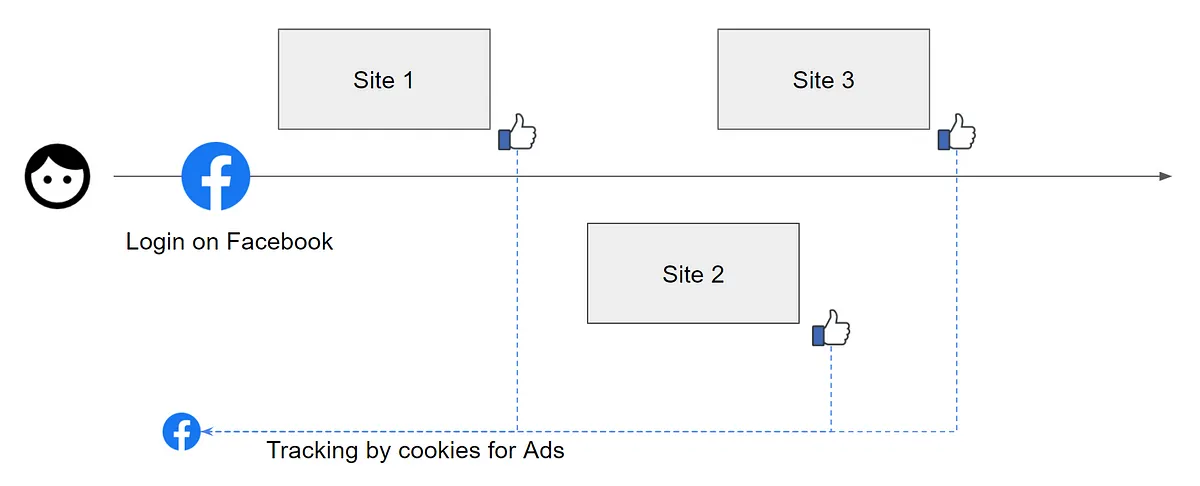
當使用者登入 Facebook 之後,Facebook 會透過 Cookie 放一段識別碼在瀏覽器裡面,當使用者造訪了有安裝 Facebook SDK 來提供「讚」功能的網頁時,瀏覽器在載入 SDK 時會再度夾帶這個識別碼,此時 Facebook 就會知道你造訪了特定的網頁並且記錄下來了。如此一來再搭配其他不同管道的追蹤方式,Facebook 就可以建構出特定使用者在網路上瀏覽的軌跡,從你的瀏覽紀錄推敲喜好,餵給你 Facebook 最想給你看的廣告了。
不過跨站追蹤也不是只能用在廣告這樣的應用上,像是 CDN (Content Delivery Network) 也是一個應用場景。CDN 服務 Cloudflare 提供服務的同時會利用 Captcha 先來確定進入網站的是不是真人或是機器人。而他希望使用者如果是真人時下次造訪同時也是採用 Cloudflare 服務的網站不要再跳出 Captcha 驗證訊息。
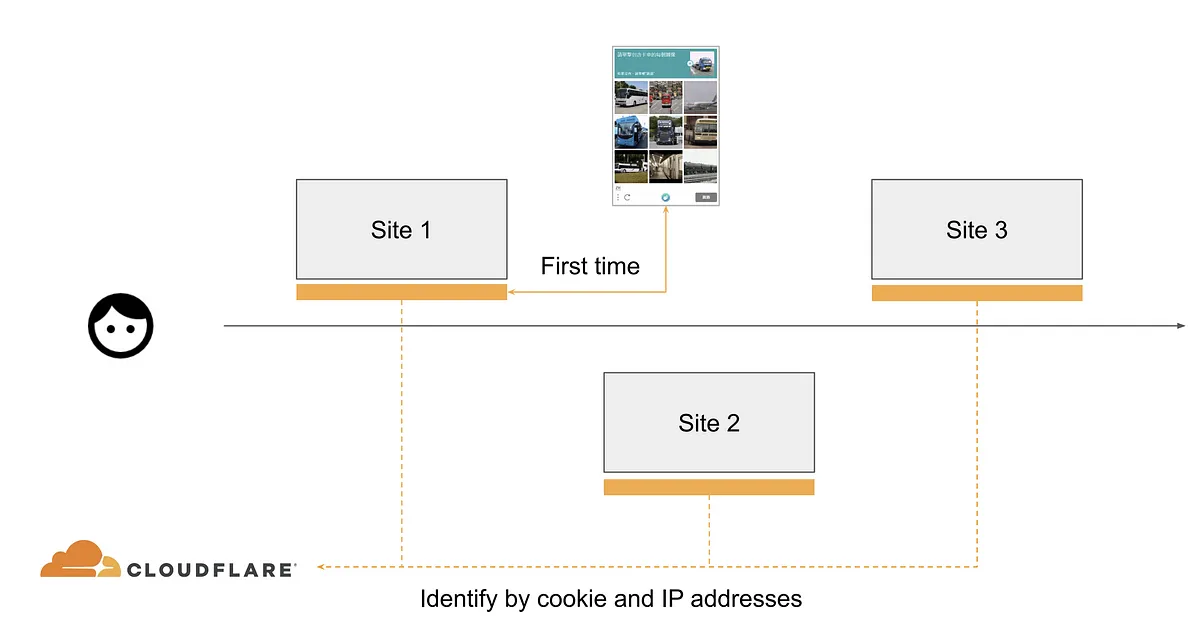
雖然 Cloudflare 也需要跨站驗證的功能來完成他們的服務,但是相較於 Google 或 Facebook 來說他們是比較沒那麼想知道使用者的隱私。有沒有什麼辦法可以保護使用者隱私的狀況下還能完成跨站驗證呢?
這就是今天要講的新 API: Trust Token。
Trust Token API - The Chromium Projects
Trust Token / Privacy Pass 簡介
Trust Token 其實是由 Privacy Pass 延伸而來。Privacy Pass 就是由 Cloudflare 所開發的實驗性瀏覽器延伸套件實作一個驗證機制,可以在不透漏過多使用者隱私的前提下實作跨站驗證。而 Trust Token 則是標準化的 Privacy Pass,所以兩個運作機制類似,但是實作方式稍有不同。
先看一下 Privacy Pass 是如何使用。因為這是實驗性的瀏覽器延伸套件所以看起來有點陽春,不過大致上還是可以了解整個概念。
{{< youtube Zn1ygWSLyzo >}}
以 hCaptcha 跟 Cloudflare 的應用為例,使用者第一次進到由 Cloudflare 提供服務的網站時,網站會跳出一些人類才可以解答的問題比如說「挑出以下是汽車的圖片」。
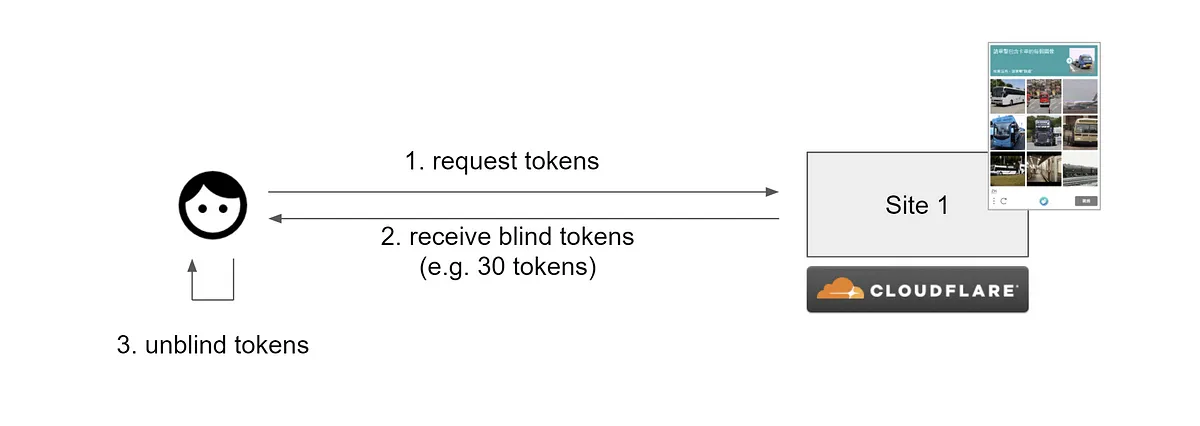
當使用者答對問題後,Cloudflare 會回傳若干組 blind token,這些 blind token 還會需要經過 unblind 後才會變成真正可以使用的 token,這個過程為 issue token。如上圖所示假設使用者這次驗證拿到了 30 個 token,在每次造訪由 Cloudflare 服務的網站時就會用掉一個 token,這個步驟稱為 redeem token。
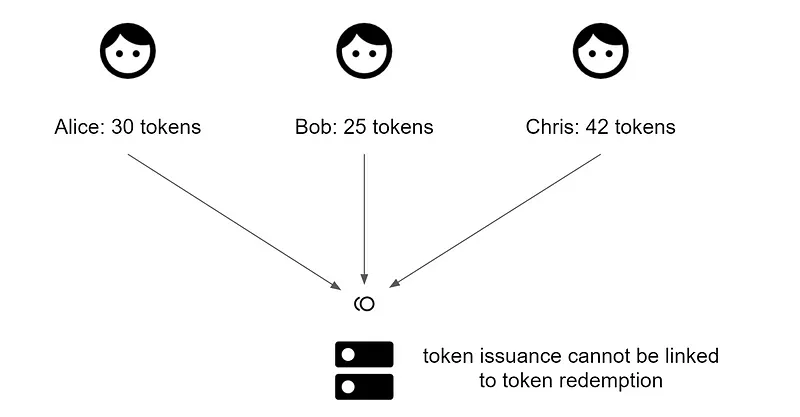
但這個機制最重要的地方在於 Cloudflare 並無法把 issue token 跟 redeem token 這兩個階段的使用者連結在一起,也就是說如果 Alice, Bob 跟 Chris 都曾經通過 Captcha 測試並且獲得了 Token,但是在後續瀏覽不同網站時把 token 兌換掉時,Clouldflare 並無法區分哪個 token 是來自 Bob,哪個 token 是來自 Alice,但是只要持有這種 token 就代表持有者已經通過了 Captcha 的挑戰證明為真人。
但這樣的機制要怎麼完成呢?以下我們會透過多個步驟的例子來解釋如何達成這個目的。不過在那之前我們要先講一下 Privacy Pass 所用到的零知識證明。
零知識證明 (Zero-knowledge proof)
零知識證明是一種方法在不揭露某個祕密的狀態下,證明他自己知道那個秘密。
Rahil Arora 在 stackexchange 上寫的比喻我覺得是相對好理解的,下面簡單的翻譯一下:
假設 Alice 有超能力可以幾秒內算出樹木上面有幾片樹葉,如何在不告訴 Bob 超能力是怎麼運作並且也不告訴 Bob 有多少片葉子的狀況下證明 Alice 有超能力?我們可以設計一個流程來證明這件事情。> Alice 先把眼睛閉起來,請 Bob 選擇拿掉樹上的一片葉子或不拿掉。當 Alice 睜開眼睛的時候,告訴 Bob 他有沒有拿掉葉子。如果一次正確的話確實有可能是 Alice 幸運猜到,但是如果這個過程連續很多次時 Alice 真的擁有數葉子的超能力的機率就愈來愈高。
而零知識證明的原理大致上就是這樣,你可以用一個流程來證明你知道某個秘密,即使你不真的揭露這個秘密到底是什麼,以上面的例子來說,這個秘密就是超能力運作的方式。
以上就是零知識證明的概念,不過要完成零知識證明有很多各式各樣的方式,今天我們要介紹的是 Trust Token 所使用的零知識證明:DLEQ。
DLEQ (Discrete Logarithm Equivalence Proof)
說明一下以下如果小寫的變數如 c, s 都是純量 (Scalar),如果是大寫如 G, H 則是橢圓曲線上面的點 (Point),如果是 vG 則一樣是點,計算方式則是 G 連續相加 v 次,這跟一般的乘法不同,有興趣可以看程式前沿的《橢圓曲線加密演算法》一文解釋得比較詳細。
DLEQ 有一個前提,在系統中的所有人都知道公開的 P 跟 Q 兩個點並且橢圓曲線群的個數是質數個或是 P 和 Q 生成的群是 isomorphism,此時以下等式會成立:
![]()
另外系統中會有兩個參考值 G 與 sG 會先公布給所有驗證者知道,G 是一個隨機點,sG 則是 Prover 用只有自己知道的祕密純量 s 對 G 運算後產生 sG。所有驗證者都可以再公開的地方得到這兩個點。
假設 Peggy 擁有一個秘密 s 要向 Victor 證明他知道 s 為何,並且在這個過程中不揭露 s 真正的數值,此時 Victor 可以產生一個隨機純量 c 以及另一個隨機點 H 傳送給 Peggy,而 Peggy 則會再產生一個隨機數 v 並且產生 r,並且附上 vG, vH, sG, sH:
r = v - cs所以 Victor 會得到 r, sG, sH, vG, vH 再加上他已經知道的 G, H。這個時候如果 Victor 計算出以下兩個等式就代表 Peggy 知道 s 的真正數值:
vG = rG + c(sG)
vH = rH + c(sH)我們舉第二個等式作為例子化簡:
vH = (v - cs)H + c(sH) // (v - cs)H 展開成 vH - csH
vH = vH - c(sH) + c(sH) // 正負 c(sH) 消掉
vH = vH這樣只有 Peggy 知道 s 的狀況下才能給出 r,所以這樣就可以證明 Peggy 確實知道 s。
因為系統已經先公開了 G 與 sG,當 Victor 傳送一個新的點 H 並且收到 sH 時,透過上面的證明就可以得知使用在 sH 上面的 s 就是原本使用在 sG 上同一個純量。
從簡易到實際的情境
Privacy Pass 網站上透過了循序漸進的七種情境從最簡單的假設到最後面實際使用的情境來講解整個機制是怎麼運作的。本文也用相同的方式來解釋各種情境,不過前面的例子就會相對比較天真一點,就請大家一步步的往下看。
基本上整個過程是透過一種叫做 Blind Signature 的方式搭配上零知識證明完成的,以下參與的角色分為 Client 與 Server,並且都會有兩個階段 issue 與 redeem token。
Scenario 1
如果我們要設計一個這樣可以兌換 token 來確認身分的系統,其中有一個方法是透過橢圓曲線 (elliptic curve) 完成。Client 挑選一個在橢圓曲線上的點 T 並且傳送給 Server,Server 收到後透過一個只有 Server 知道的純量 (scalar) s 對 T 運算後得到 sT 並且回傳給 Client,這個產生 sT 的過程稱為 Sign Point,不過實際上運作的原理就是橢圓曲線上的連續加法運算。
SignPoint(T, s) => sT等到 Client 需要兌換時只要把 T 跟 sT 給 Server,Server 可以收到 T 的時候再 Sign Point 一次看看是不是 sT 就知道是否曾經 issue 過這個 token。
Issue
以下的範例,左邊都是 Client, 右邊都是 Server。 -> 代表 Client 發送給 Server,反之亦然。
// Client 發送 T 給 Server, 然後得到 sT
T ->
<- sTRedeem
// Client 要 redeem token 時,傳出 T 與 sT
T, sT ->問題:Linkability
因為 Server 在 issue 的時候已經知道了 T,所以基本上 Server 可以透過這項資訊可以把 issue 階段跟 redeem 階段的人連結起來進而知道 Client 的行為。
Scenario 2
要解決上面的問題,其中一個方法是透過 Blind Signature 達成。Client 不送出 T,而是先透過 BlindPoint 的方式產生 bT 跟 b,接下來再送給 Server bT。Server 收到 bT 之後,同樣的透過 Sign Point 的方式產生結果,不一樣的地方是情境 1 是用 T,而這邊則用 bT 來作 Sign Point,所以得出來的結果是 s(bT)。
Client:
BlindPoint(T) => (bT, b)
Server:
SignPoint(bT, s) => sbT而 Blind Signature 跟 Sign Point 具備了交換律的特性,所以得到 s(bT) 後可以透過原本 Client 已知的 b 進行 Unblind:
UnblindPoint(sbT, b) => sT這樣一來在 Redeem 的時候就可以送出 T, sT 給 Server 了,而且透過 SignPoint(T, s) 得出結果 sT’ 如果符合 Client 傳來的 sT 就代表確實 Server 曾經簽過這個被 blind 的點,同時因為 T 從來都沒有送到 Server 過,所以 Server 也無法將 issue 與 redeem 階段的 Client 連結在一起。
Issue
bT ->
<- s(bT)Redeem
T, sT ->問題:Malleability
以上的流程其實也有另外一個大問題,因為有交換律的關係,當 Client 透過一個任意值 a 放入 BlindPoint 時產生的 a(sT) 就會等於 s(aT):
BlindPoint(sT) => a(sT), a
// a(sT) === s(aT)此時如果將 aT 跟 s(aT) 送給 Server Redeem,此時因為
SignPoint(aT, s) => s(aT)所以就可以兌換了,這樣造成 Client 可以無限地用任意數值兌換 token。
Scenario 3
這次我們讓 Client 先選擇一個純數 t,並且透過一種單向的 hash 方式來產生一個在橢圓曲線上的點 T,並且在 redeem 階段時原本是送出 T, sT 改成送出 t, sT。
因為 redeem 要送出的是 t,上個情境時透過任意數 a 來產生 s(aT) 的方法就沒辦法用了,因為 t 跟 sT 兩個參數之間並不是單純的再透過一次 BlindPoint() 就可以得到,所以就沒辦法無限兌換了。
Issue
T = Hash(t)
bT ->
<- sbTRedeem
t, sT ->問題:Redemption hijacking
在這個例子裏面,Client 其實是沒有必要傳送 sT 的,因為 Server 僅需要 t 就可以計算出 sT,額外傳送 sT 可能會導致潛在的 Redemption hijacking 問題,如果在不安全的通道上傳輸 t, sT 就有可能這個 redemption 被劫持作為其他的用途。
不過在網站上沒講出實際上要怎麼利用這個問題,但是少傳一個可以計算出來的資料總是好的。Client 只要證明他知道 sT 就好,而這可以透過 HMAC (Hash-based Message Authentication Code) 達成。
Scenario 4
步驟跟前面都一樣,唯一不一樣的地方是 redeem 的時候原本是傳 t, sT,現在則改傳 t, M, HMAC(sT, M),如果再介紹 HMAC 篇幅會太大,這邊就不解釋了,但可以是作是一個標準的 salt 方式讓 Hash 出來的結果不容易受到暴力破解。
這樣的特性在這個情境用很適合,因為 Server 透過 t 就可以計算出 sT,透過公開傳遞的 M 可以輕易地驗證 client 端是否持有 sT。
Issue
T = Hash(t)
bT ->
<- sbTRedeem
t, M, HMAC(sT, M) ->問題:Tagging
這邊的問題在於 Server 可以在 issue 階段的時候用不一樣的 s1, s2, s3 等來發出不一樣的 sT’,這樣 Server 在 Redeem 階段就可以得知 client 是哪一個 s。所以 Server 需要證明自己每次都用同樣的 s 同時又不透漏 s 這個純量。
要解決這個問題就需要用到前面我們講解的零知識證明 DLEQ 了。
Scenario 5
前面的 DLEQ 講解有提到,如果有 Peggy 有一個 s 秘密純量,我們可以透過 DLEQ 來證明 Peggy 知道 s,但是又不透漏 s 真正的數值,而在 Privacy Pass 的機制裡面,Server 需要證明自己每次都用 s,但是卻又不用揭露真正的數值。
在 Issue 階段 Client 做的事情還是一樣傳 bT 給 Server 端,但 Server 端的回應就不一樣了,這次 Server 會回傳 sbT 與一個 DLEQ 證明,證明自己正在用同一個 s。
首先根據 DLEQ 的假設,Server 會需要先公開一組 G, sG 給所有的 Client,並且在證明時傳另外一個點 H 給 Prover。而在 Privacy Pass 的實作中則是將 H 則改用 bT 代替。
回傳的時候 Server 要證明自己仍然使用同一個 s 發出 token,所以附上了一個 DLEQ 的證明 r = v - cs,Client 只要算出以下算式相等就可證明 Server 仍然用同一個 s (記住了 H 已經改用 bT 代替,此時 client 也有 sbT 也就是 sH):
vH = rH + c(sH) // H 換成 bT
vbT = rbT + c(sbT) // 把 r 展開成 v - cs
vbT = (v - cs)bT + c(sbT) // (v - cs)bT 展開成 vbT - csbT
vbT = vbT - c(sbT) + c(sbT) // 正負 c(sbT) 消掉
vbT = vbT這樣就可以證明 Server 在 sbT 上用的 s 跟 sG 上面用的是同一個。
Issue
T = Hash(t)
bT ->
<- sbT, DLEQ(bT:sbT == G:sG)Redeem
t, M, HMAC(sT, M) ->問題:only one redemption per issuance
到這邊基本上 Privacy Pass 的原理已經解釋得差不多了,不過這邊有個問題是一次只發一個 token 太少,應該要一次可以發多個 token。這邊我要跳過源文中提到的 Scenario 6 解釋最後的結果。
Scenario 7
由於一次僅產生一個 redeem token 太沒效率了,如果同時發很多次,每次都產生一個 proof 也不是非常有效率,而 DLEQ 有一個延伸的用法 “batch” 可以一次產生多個 token, 並且只有使用一個 Proof 就可以驗證所有 token 是否合法,這樣就可以大大的降低頻寬需求。
不過這邊我們就不贅述 Batch DLEQ 的原理了,文末我會提及一些比較有用的連結跟確切的源碼片段讓有興趣的人可以更快速的追蹤到源碼片段。
Issue
T1 = Hash(t1)
T2 = Hash(t2)
T3 = Hash(t3)
b1T1 ->
b2T2 ->
b3T3 ->
c1,c2,c3 = H(G,sG,b1T1,b2T2,b3T3,s(b1T1),s(b2T2),s(b3T3))
<- sb1T1
<- sb2T2
<- sb3T3
<- DLEQ(c1b1T1+c2b2T2+c3b3T3:s(c1b1T1+c2b2T2+c3b3T3) == G: sG)Redeem
t1, M, HMAC(sT1, M) ->結論
Privacy Token / Trust Token API 透過零知識證明的方式來建立了一個不需要透漏太多隱私也可以達成跟 cookie 相同效果的驗證方式,期待可以改變目前許多廣告巨頭透過 cookie 過分的追蹤使用者隱私的作法。
不過我在 Trust Token API Explainer 裡面看到這個協議裡面的延伸作法還可以夾帶 Metadata 進去,而協議制定的過程中其實廣告龍頭 Google 也參與其中,希望這份協議還是可以保持中立,盡可能地讓最後版本可以有效的在保護隱私的情況下完成 Cross-domain authorization 的功能。
參考資料
IETF Privacy Pass docs
Cloudflare
- Supporting the latest version of the Privacy Pass Protocol (cloudflare.com)
- Chinese: Cloudflare 支持最新的 Privacy Pass 扩展_推动协议标准化
Other
- Privacy Pass official website
- Getting started with Trust Tokens (web.dev)
- WICG Trust Token API Explainer
- Non-interactive zero-knowledge (NIZK) proofs for the equality (EQ) of discrete logarithms (DL) (asecuritysite.com) 這個網站非常實用,列了很多零知識證明的源碼參考,但可惜的是 DLEQ 這個演算法講解有錯,讓我在理解演算法的時候撞牆很久。所以使用的時候請多加小心,源碼應該是可以參考的,解釋的話需要斟酌一下。
關鍵源碼
這邊我貼幾段覺得很有用的源碼。
- privacy pass 提供的伺服器端產生 Proof 的源碼
- privacy pass 提供的瀏覽器端產生 BlindPoint 的源碼
- github dedis/kyber 產生 Proof 的源碼
修訂
- 2020/12/26: 新增了 G 跟 sG 的說明並且把之前關於這部分的錯誤敘述修改了一下
- 2020/12/30: 根據 ChihYun Chuang 的評論在 DLEQ 解釋一節加入一個假設,詳情請見評論。
— ,